About Lesson
In this Python NLP lesson we are going to learn about Python NLP Bigrams, so bigrams are two consecutive words that occurred in a text. or a bigram is a sequence of two adjacent elements from a string of tokens, which are typically letters, or words like rain bow, john doe, heavy rain.
Now let’s create an example.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
from nltk.corpus import webtext, stopwords from nltk import bigrams from nltk.probability import FreqDist text_data = webtext.words('grail.txt') stop_words = set(stopwords.words('english')) filtered_words = [] for word in text_data: if word not in stop_words: if len(word) > 3: filtered_words.append(word) #now we are going to use bigrams for this bigram = bigrams(filtered_words) freq_dist = FreqDist(bigram) |
So now if you run this code, you will receive this result, you can see that we have two consecutive words.
|
1 2 3 4 5 |
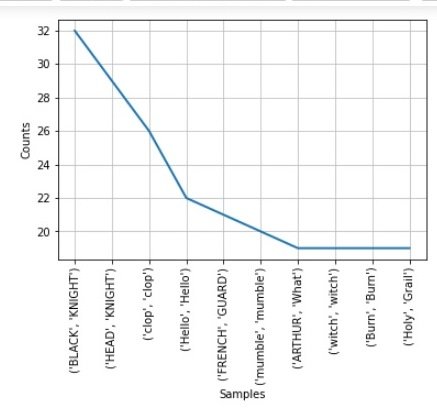
FreqDist({('BLACK', 'KNIGHT'): 32, ('HEAD', 'KNIGHT'): 29, ('clop', 'clop'): 26, ('Hello', 'Hello'): 22, ('FRENCH', 'GUARD'): 21, ('mumble', 'mumble'): 20, ('ARTHUR', 'What'): 19, ('witch', 'witch'): 19, ('Burn', 'Burn'): 19, ('Holy', 'Grail'): 19, ...}) |
You can print the most 10 commons words.
|
1 |
print(freq_dist.most_common(10)) |
Also you can plot the frequency distribution using this code.
|
1 |
freq_dist.plot(10) |
This will be the result.