In this Python NLP lesson we are going to learn about Python NLP Stop Words, so in Natural Language Processing Stopwords are words that generally do not contribute to the meaning of a sentence, for example stop word are like ( “the”, “a”, “an”, “in”) that a search engine has been programmed to ignore, both when indexing entries for searching and when retrieving them as the result of a search query. for the purposes of information retrieval and natural language processing. NLTK comes with a pre-built list of stop words for around 22 languages.
These are different languages that are available in Stop Words, now let’s check the languages using this code.
|
1 2 3 |
from nltk.corpus import stopwords print(stopwords.fileids()) |
If you run the code this will be the available languages for the stopwords.
|
1 2 3 4 5 6 7 |
['arabic', 'azerbaijani', 'danish', 'dutch', 'english', 'finnish', 'french', 'german', 'greek', 'hungarian', 'indonesian', 'italian', 'kazakh', 'nepali', 'norwegian', 'portuguese', 'romanian', 'russian', 'slovene', 'spanish', 'swedish', 'tajik', 'turkish'] |
Let’s check the stopwords list for English language, you can see when you are using stop words you need to specify the language.
|
1 2 3 4 5 6 7 |
from nltk.corpus import stopwords #config the language stop_words = stopwords.words('english') print(stop_words) |
These Stopwords are available for English language.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', "you're", "you've", "you'll", "you'd", 'your', 'yours', 'yourself', 'yourselves', 'he', 'him', 'his', 'himself', 'she', "she's", 'her', 'hers', 'herself', 'it', "it's", 'its', 'itself', 'they', 'them', 'their', 'theirs', 'themselves', 'what', 'which', 'who', 'whom', 'this', 'that', "that'll", 'these', 'those', 'am', 'is', 'are', 'was', 'were', 'be', 'been', 'being', 'have', 'has', 'had', 'having', 'do', 'does', 'did', 'doing', 'a', 'an', 'the', 'and', 'but', 'if', 'or', 'because', 'as', 'until', 'while', 'of', 'at', 'by', 'for', 'with', 'about', 'against', 'between', 'into', 'through', 'during', 'before', 'after', 'above', 'below', 'to', 'from', 'up', 'down', 'in', 'out', 'on', 'off', 'over', 'under', 'again', 'further', 'then', 'once', 'here', 'there', 'when', 'where', 'why', 'how', 'all', 'any', 'both', 'each', 'few', 'more', 'most', 'other', 'some', 'such', 'no', 'nor', 'not', 'only', 'own', 'same', 'so', 'than', 'too', 'very', 's', 't', 'can', 'will', 'just', 'don', "don't", 'should', "should've", 'now', 'd', 'll', 'm', 'o', 're', 've', 'y', 'ain', 'aren', "aren't", 'couldn', "couldn't", 'didn', "didn't", 'doesn', "doesn't", 'hadn', "hadn't", 'hasn', "hasn't", 'haven', "haven't", 'isn', "isn't", 'ma', 'mightn', "mightn't", 'mustn', "mustn't", 'needn', "needn't", 'shan', "shan't", 'shouldn', "shouldn't", 'wasn', "wasn't", 'weren', "weren't", 'won', "won't", 'wouldn', "wouldn't"] |
So now let’s remove stop words from this text. in this example we are going to get non stop words from this text. the non stop words in this text are [first, example, nltk].
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
from nltk.corpus import stopwords from nltk.tokenize import word_tokenize mytext = "this is my first example in nltk for you" stop_words = set(stopwords.words('english')) words = word_tokenize(mytext) filtered_words = [] for word in words: if word not in stop_words: filtered_words.append(word) print(filtered_words) |
If you run the code this will be the result.
|
1 |
['first', 'example', 'nltk'] |
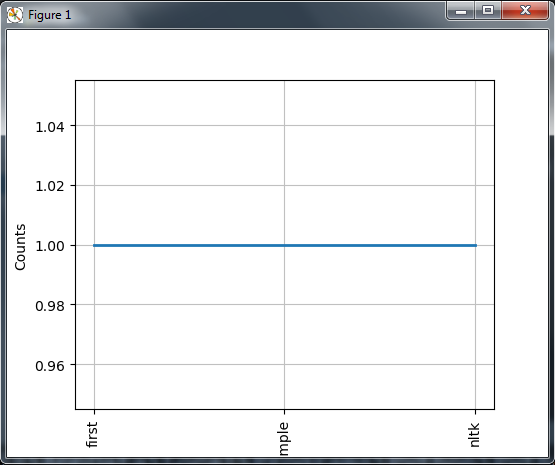
Also you can see the frequency distribution of a word in a sentence using this code, we have also plotted the most used words.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
from nltk.corpus import stopwords from nltk.tokenize import word_tokenize from nltk.probability import FreqDist mytext = "this is my first example in nltk for you" stop_words = set(stopwords.words('english')) words = word_tokenize(mytext) filtered_words = [] for word in words: if word not in stop_words: filtered_words.append(word) print(filtered_words) freq_dist =FreqDist(filtered_words) print(freq_dist.most_common()) freq_dist.plot() |
If you run the code this is the result. you can see that every word is used one time in the text.
|
1 |
[('first', 1), ('example', 1), ('nltk', 1)] |
And this is the plot.